
-
Programming Jan-April 2024
This year started off pretty light when it came to programming because I’ve been addicted to the video game Against the Storm since last winter. But I eventually started working again on various projects – some old and some new. I didn’t do any programming in January, so we’ll start in February. February and March…
-
A few thoughts on Programming languages

Just a few thoughts on programming languages that have been rattling around in my head this week, but which don’t each merit a full blog post. The main theme is that the culture behind each programming language leads to some interesting choices, as is the case with spoken languages. This week I started learning how…
-
Programming Update: March 2023
In March I continued to work on my programming projects as well as a little more Advent of Code. Things started off with me finishing up my dreamhostapi and Dreamhost_DNS_Go projects in Golang. I got the API working under all the conditions that I need and I worked on both the output of the program…
-
Programming Update: December 2022

December was wholly dedicated to solving the Advent of Code 2022 problem set. Our job was to help the elves trek through the jungle to get magical starfruit. It was a lot of fun to do it live once again! This year I also had experience from the previous years (both live and on my…
-
Software I used for Programming in 2022
Python This year I really worked a lot on Python web technologies so I came to appreciate all the work that the JetBrains team does to make all the little things (like running Django test server commands) incredibly easy. I essentially did all my Python development in Pycharm. I’ve had access to the paid JetBrains…
-
Programming Update: Nov 2022
November was not a huge programming month for me. On the weekends I was a little more focused with family stuff and videogames. But I did manage work on a couple projects. Ever since 2010, I’ve been been using Python to automatically post my top 3 artists to Twitter. In 2020, it even became my…
-
Review: Data Visualization with Python and JavaScript: Scrape, Clean, Explore & Transform Your Data
Data Visualization with Python and JavaScript: Scrape, Clean, Explore & Transform Your Data by Kyran Dale My rating: 4 of 5 stars While a book about web technologies is undoubtablely going to get out of date (especially when Javascript is involved), I would definitely recommend this book if you want to do some data visualization…
-
Review: Flask Web Development: Developing Web Applications with Python
Flask Web Development: Developing Web Applications with Python by Miguel Grinberg My rating: 5 of 5 stars I read the second edition of the book I’ve read lots of books covering web frameworks or GUI programming (both involve UI design and a different workflow where you’re often waiting for user input), but this one is…
-
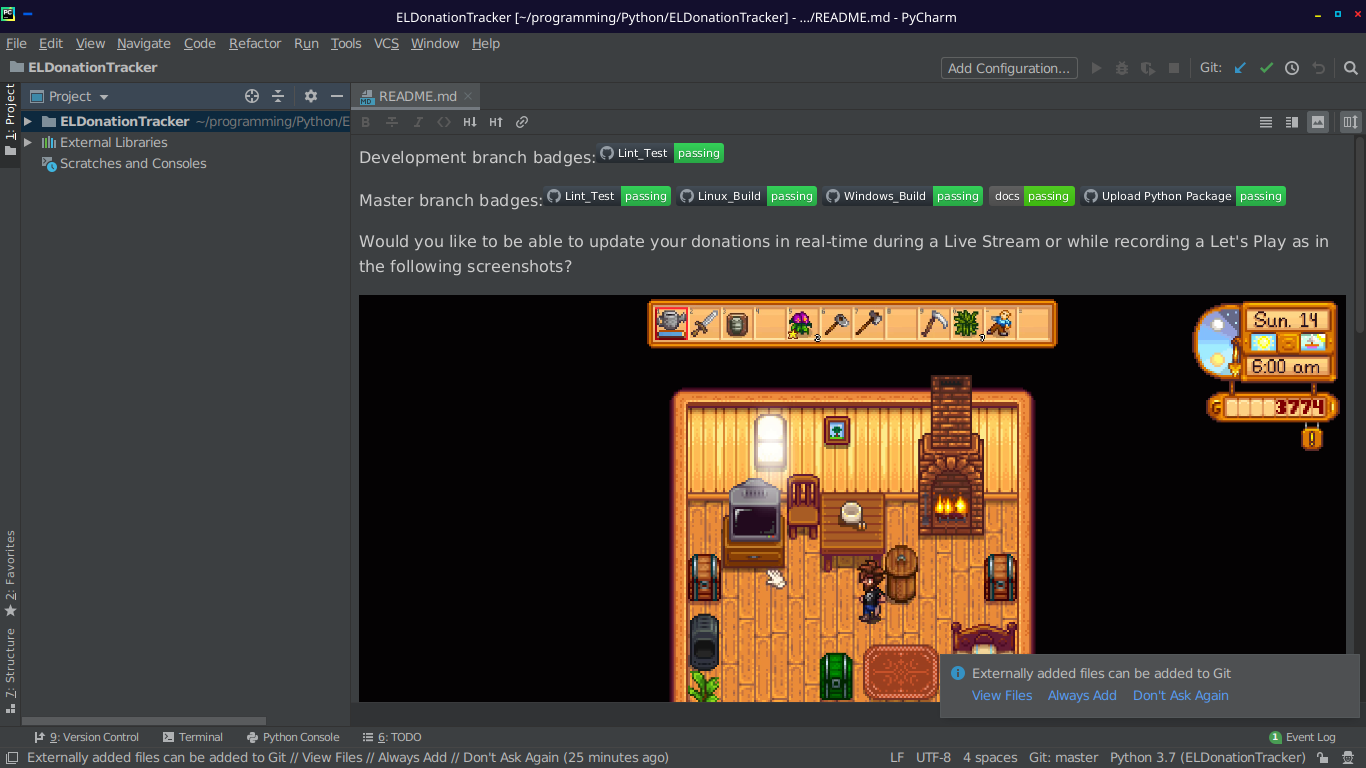
Programming Update: October 2022
As October came around, it was time to get ready for Hacktoberfest. I’ve been participating for the past few years and I love the fact that DigitalOcean supports this project which gets more people to contribute to free and open source software. In the past, I’ve often contributed to my Extra Life Donation Tracker. Since…
-
Programming Update: Aug
August was a programming-filled month for me. It focused entirely on Python and I mostly continued working on established projects. Let’s jump in! Amortization I wanted to re-calculate the amortization table for my home loan for the first time in about a year. As a refresher, I created this program (vs using Excel or an…
-
Course Review: Modern APIs with FastAPI, MongoDB and Python
I’ve attended a few of Michael Kennedy’s Python courses over at TalkPython.fm. He’s a great instructor and he really knows his Python. (As well he should, as host of Talk Python and co-host of Python Bytes) His usual courses at Talk Python are pre-recorded and I believe this was Michael’s first time doing an online…
-
Programming Update May-July 2022
I started working my way back towards spending more time programming as the summer started (in between getting re-addicted to CDProjektRed’s Gwent). I started off by working on my btrfs snapshot program, Snap in Time. I finally added in the ability for the remote culling to take place. (My backup directories had started getting a…
-
Programming Update: March/April
In March I went back to Advent of Code 2016. In an effort not to get stuck, I decided to go as far as I can in Python before going back around and working on the other languages. So I did days 6 and 7 in Python. Overall, relatively easy Regex problems. And that’s it.…
-
Programming Update: January/February 2022
I started off the year not expecting to do much programming. Compared to some months in 2021, I barely programmed, but I did end up programming much more than I expected. Let’s take a look at what I worked on in the first sixth of the year. Python Programs End of Year Video Games Helper…
-
Programming Update: November/December 2021
In these last two months of the year I only worked on Advent of Code. November In November I worked through part of the 2016 problem set. I didn’t get too far because of how many languages I was doing at this point. Eventually I decided to allow myself to get a bit further in…