-
Review: Eve: How the Female Body Drove 200 Million Years of Human Evolution
Eve: How the Female Body Drove 200 Million Years of Human Evolution by Cat Bohannon My rating: 5 of 5 stars I loved listening to this book. The author (also the narrator) does an incredible job taking a look at every difference between male and female bodies and explaining the current scientific knowledge about when…
-
Review: Starter Villain
Starter Villain by John Scalzi My rating: 4 of 5 stars Just like Scalzi’s previous book, The Kaiju Preservation Society, this one is a real popcorn book. It’s also got a pretty silly movie-inspired premise and I consider them to be in a meta series. As the book blurb says, our protagonist inherits his Uncle’s…
-
Review: Night Watch
Night Watch by Terry Pratchett My rating: 4 of 5 stars this is my second time reading the book. The rating remains 4/5 stars. I didn’t remember liking this book so much given the fact that I’m not much of a fan of time loops, at least, not since I got use to the idea.…
-
Review: Golden Age and Other Stories
Golden Age and Other Stories by Naomi Novik My rating: 4 of 5 stars A neat collection of short stories that take place in the world of the Temeriare series. Some of them are simultaneous with the series and some take place afterwards. It’s a fun little reunion with our friends from the last 9…
-
2023 Game of the Year

In my 2022 year-end blog post, I thought I was going to focus more on finishing up the narrative video games I started in the prior years. I definitely made some good progress on Disco Elysium, but not nearly as much as I wanted. I didn’t finish any of the narrative games. In January, I…
-
What 8bitDo can learn from the Competition (and also what 8bitDo is doing better!)

I’m all-in on 8bitDo. Prior to getting on the 8bitDo train, I was mainly focused on PC gaming, so I would get Xbox controllers (whatever the latest was at the time). But with 8bitDo supporting PC, Switch, Android, and (I think) the Xbox and PS4/5 with addaptors – it’s a no-brainer to go with 8bitDo,…
-
Review: League of Dragons
League of Dragons by Naomi Novik My rating: 4 of 5 stars A perfect ending to the Temeriare series. There’s finally an ending to the Napoleonic threat – I won’t say whether it follows the same trajectory as in our world. But, more importantly, we finally begin to see dragons finally understand their place in…
-
Review: Mislaid in Parts Half-Known
Mislaid in Parts Half-Known by Seanan McGuire My rating: 4 of 5 stars Since this novella only just came out on Tuesday (a few days ago), I’m going to be very careful about any spoilers other than what can easily be inferred from the back of the book description. McGuire has formed a main clique…
-
2023 in Music (Last.FM and Spotify Listening Trends)
Another year has ended and so it’s time to take a look at the music I listened to all year. First of all, it was yet another year in which I grew my personal music collection. I’ve seen more an more artists removed from places like Spotify, Apple Music, etc, so it’s still important to…
-
Review: Thief of Time
Thief of Time by Terry Pratchett My rating: 3 of 5 stars This is my second time reading this book. I left the rating at 3/5 I debated dropping the rating to 2 stars (“It was OK”), but Lu-Tze was enough to keep it at 3 stars. I am not sure if we learned his…
-
Review: Lightspeed Magazine, Issue 112, September 2019
Lightspeed Magazine, Issue 112, September 2019 by John Joseph Adams My rating: 4 of 5 stars Even though AI has been a constant subject in science fiction for nearly 100 years now, it’s interesting reading the two AI-related stories in the 2023, the year of ChatGPT. Although ChatGPT is still far away from general AI,…
-
Review: Blood of Tyrants
Blood of Tyrants by Naomi Novik My rating: 4 of 5 stars Oh, Temeriaire, you sweet summer child-dragon (to mix together 2 vastly different dragon-containing series). Yes, you’re learning, but you still are way too optimistic about people, dragons, and battles. This was one of the better Temeriare novels, although so far they’ve all been…
-
My 2023 Programming Progress
In 2023 I just didn’t have the urge to do as much programming as in years past. I felt more of a tug towards video games, reading, and baking/cooking. So this recap will be quite a bit shorter than usual. A couple upfront themes and ideas: The programming was essentially Go and Python. I started…
-
My Reading Life in 2023
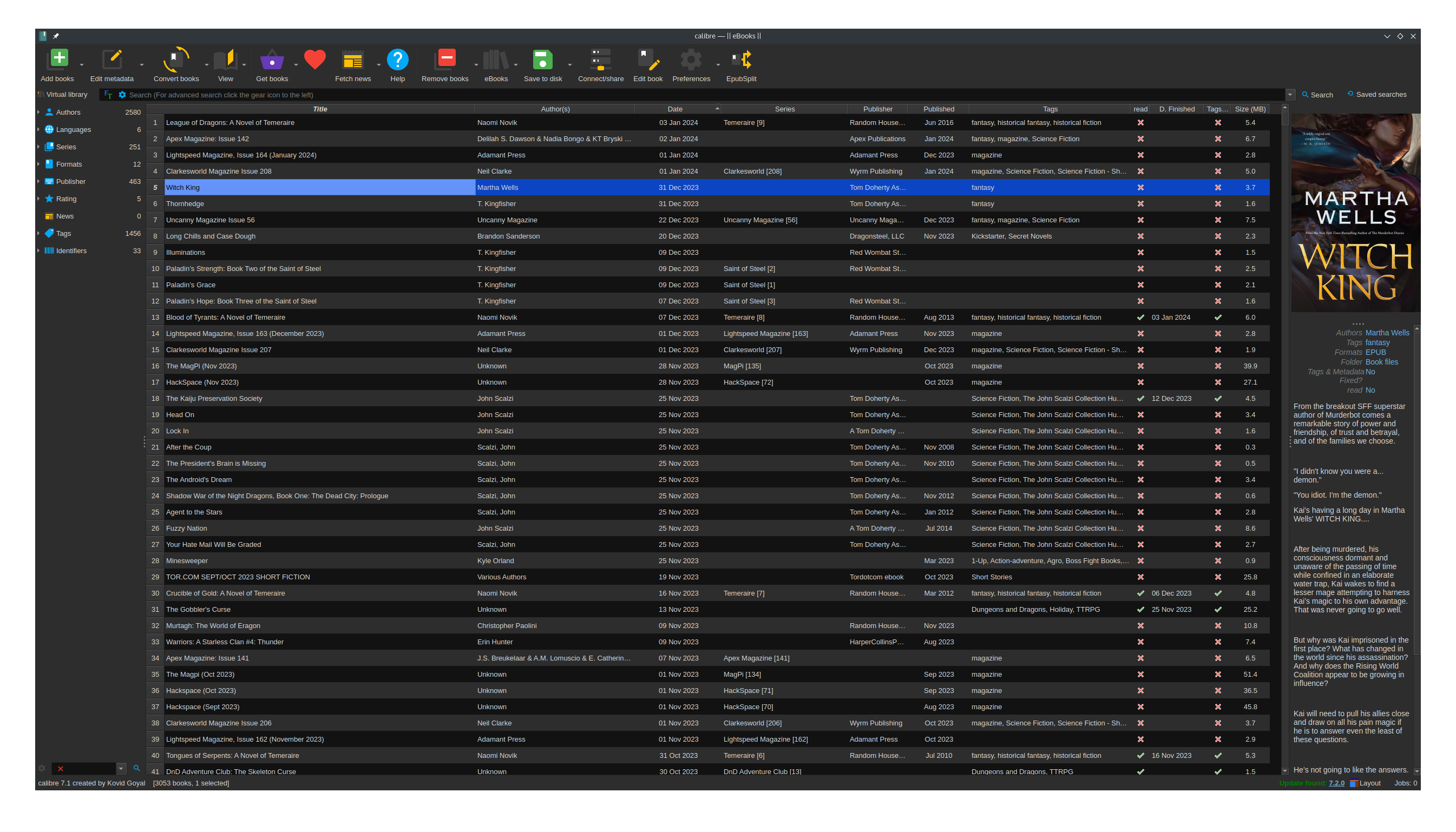
By the end of 2023 I had 3049 ebooks and magazines (a change of 256 – pretty even with last year). Of those, 2434 were unread. Some chunk of those – maybe as much as ¼ were giveaways like Raspberry Pi Magazine, HackSpace Magazine, and Tor.com book club freebies. I stopped getting the monthly free…
-
Review: Lightspeed Magazine, Issue 111, August 2019
Lightspeed Magazine, Issue 111, August 2019 by John Joseph Adams My rating: 4 of 5 stars This issue was one in which I enjoyed all of the stories very much. Science Fiction One Thousand Beetles in a Jumpsuit (Dominica Phetteplace) – a dystopian story taking place “20 Minutes in the Future” that seems to me…

It's A Binary World 2.0
Insights on fatherhood, technology, culture, photography, and politics